识别图像物块实现
一、摄像头调整
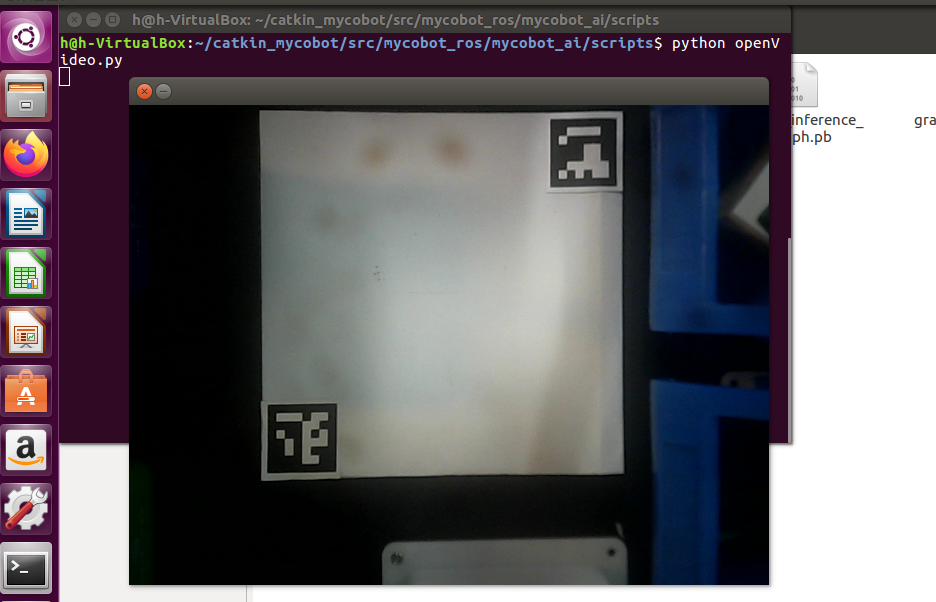
首先,需要使用python运行mycobot_ai包下的openVideo.py。若开启的摄像头为电脑摄像头这需要修改cap_num,具体可参考:注意事项。确保摄像头完全包含整个识别区域,且识别区域在视频中是正正方方的,如下图所示。若识别区域在视频中不符合要求,则需要调整摄像头的位置。
二、案例重现
如上视频操作即可实现图图片识别物块并抓取的demo。接下来我们将用文字描述视频中的操作流程:
M5版本:
- 通过文件管理器去到mycobot-ros的工作空间中的mycobot_ai包下。
- 鼠标右键,打开终端。
- 赋予操作机械臂权限,输入
sudo chmod 777 /dev/ttyU并使用Tab键补出机械臂设备名称。 - 若设备名称不为
/dev/ttyUSB0则需要更改vision.launch文件中的port值。 - 输入
roslaunch launch/vision.launch开启vision.launch文件,该文件包含ros的一些核心库以及依赖等。 - 在rviz图形界面中创建一个marker,并为其命名为cube。
- 在命令终端中键入
ctrl+shift+t开启同目录下的另一个命令窗口。 - 输入
python scripts/detect_obj_img.py打开识别颜色程序,即可实现颜色识别并抓取了。
若不清楚如何修改port值以及创建marker可参考:ROS建立方块模型
树莓派版本:
一 在文件终端使用方法:
- 开机点击桌面Home文档,之后点击catkin_ws文档——src文档——mycobot_ros未定。
- 点击mycobot_ai,进入界面鼠标右键,打开终端。
- 输入roslaunch launch/vision.launch开启vision.launch文件,该文件包含ros的一些核心库以及依赖等。
- 在rviz图形界面中创建一个marker,并为其命名为cube。
- 在命令终端中键入ctrl+shift+t开启同目录下的另一个命令窗口。
- 输入python scripts/detect_obj_img.py打开识别颜色程序,即可实现颜色识别并抓取了。
二 桌面终端使用方法:
- 鼠标右键点击ai_windows,打开终端,输入python3 ai_windows.py,按回车开启gui。
- 打开gui界面,先点击“open ros按钮”打开ros。
- 等待ros打开完毕,选择图像识别程序,点击运行即可。
- 可以添加特征点多的图像,实现图像识别分拣,使用方法gui界面有说明。
注意事项
- 当摄像头没有正确自动框出识别区域需要关闭程序,调整摄像头的位置,可将摄像头向左向右移动等操作;光线会影响摄像头不识别,可适当补光。
- 若命令终端没有出现ok,且无法识别图片时,需要将摄像头稍微向后或向前移动一下,当命令终端出现ok时程序即可正常运行。
由于物块中的图片物体较小,为了更好的识别图片需要将物块反放在识别区域。

OpenCV图像识别会受环境的影响,若处在较为昏暗的环境下识别效果将大大降低。
三、代码讲解
本案例是基于OpenCV以及ROS通信控制机械臂实现的。首先,对摄像头进行校准,确保摄像头的准确性。通过识别抓取范围内的两个aruco码智能定位识别范围,并确定实际识别范围的中心点与视频像素点位之间的对应关系。使用OpenCV加载tensorflow训练出来的图片识别模型,使用训练模型对图片进行一系列的区域筛选,识别并定位图片中的物体。根据物块在视频中的像素点与实际识别范围中心的视频像素点计算出物块相对于实际识别范围中心的坐标情况,之后根据实际识别范围中心与机械臂的相对坐标可计算出物块相对于机械臂的相对坐标。最后通过设计一系列动作抓取物块并放置到相应的桶中。
是否觉得跟上一个案例很相似?没错,我们只需将颜色识别模块代替为物体识别模块即可完成图片识别抓取物体的功能。
物体识别
在自定义类的初始化中,加载tensorflow训练出来的图片识别模型。对图片进行大小调整以及从BGR转换到RGB,然后使用模型对图片进行检测。处理检测结果并在图片中框出物块、给出相应信息。
def obj_detect(self, frame):
rows, cols = frame.shape[:-1]
# 调整大小的图像和交换BGR到RGB。
blob = cv2.dnn.blobFromImage(
frame,
size=(300, 300),
mean=(0, 0, 0),
swapRB=True,
crop=False,
)
# 检测图片
self.net.setInput(blob)
out = self.net.forward()
x, y = 0, 0
# 处理结果
for detection in out[0, 0, :, :]:
score = float(detection[2]) # 获取置信度
if score > 0.3:
# 物体id
class_id = detection[1]
# 物体在图片中的位置信息
left = detection[3] * cols
top = detection[4] * rows
right = detection[5] * cols
bottom = detection[6] * rows
if abs(right + bottom - left - top) > 380:
continue
x, y = (left + right) / 2.0, (top + bottom) / 2.0
# 将物体在图片中框出
cv2.rectangle(
frame,
(int(left), int(top)),
(int(right), int(bottom)),
(0, 230, 0),
thickness=2,
)
# 在图片中添加物体识别信息
cv2.putText(
frame,
"{}: {}%".format(self.id_class_name(class_id),round(score * 100, 2)),
(int(left), int(top) - 10),
cv2.FONT_HERSHEY_COMPLEX_SMALL,
1,
(243, 0, 0),
2,
)
if x+y > 0:
return x, y
else:
return None
具体代码可直接查看程序源文件,查看代码中的注释。若对重点模块不太了解可参考上一个案例。